Assigned: 11/13/14
Due: 11/24/14
In this assignment, you will perform a speaker diarization task. We have made many simplifications to the task outlined in this assignment as compared to a real-world speaker diarization task, in an effort to make it more relevant to the material taught in the lectures.
Delacourt, Perrine. "SEGMENTATION ET INDEXATION PAR LOCUTEURS D’UN DOCUMENT AUDIO.", 1998
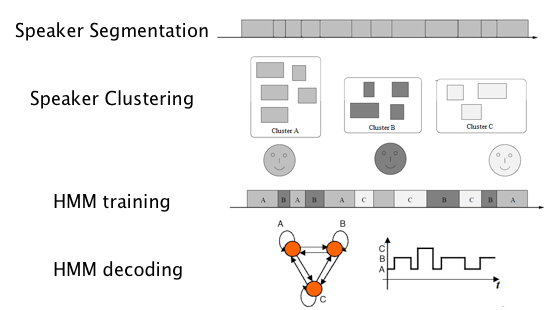
In this experiment, we have a WAV file that includes a conversation between 4 speakers. Our goal is to learn the speech of each speaker, and then specify “which speaker is speaking at a any given time”. Think about a situation in which you have to listen to conversation of 4 people (who are unknown to you ahead of time), and your job is to transcribe that when is a certain speaker talking (you can code speaker to A, B, etc). For example, if you were transcribing an audio recording of a meeting.
Note: For installing hmmlearn, first, clone the library from its repository. Unfortunately there is a bug that happens during the installation. For solving that, first fix hmmlearn/setup.py as described here: https://github.com/hmmlearn/hmmlearn/issues/7 . The goal is to add “utils” package to the installation, which does not happen by default. Then cd to the main directory and write “sudo python setup.py install”.
Let us know if you have installation issues.
The data is the “IB4001” conversation that is extracted from the AMI corpus (http://groups.inf.ed.ac.uk/ami/). Each conversation has a .wav file and a .xml file that includes the speaker segments. This conversation is 29 minutes long.
From the .wav file, we extracted the 13th order MFCC features using scikits.talkbox toolkit. We also included the F0 pitch value, which we extracted using The Snack Sound Toolkit (for more on speech features, refer to EE 506/606 Speech Signal Processing course taught by Alexander Kain). The resulting data is in a sequence with dimensions 178060x14 - 178060 observations, each with 14 dimensions. The 178060x1 state sequences (speaker labels) were extracted from the xml files. For simulating a real-world speaker diarization task, we also corrupted the speaker labels (20% corruption level— i.e., 1 in every 5 labels is randomly corrupted).
You will be provided the following data:
You can read the above variables by:
import pickle
f=open(’data.pkl’, ’r’)
observation=pickle.load(f)
states=pickle.load(f)
seg_clus=pickle.load(f)
f.close()
You can study the attributes of the hmmlearn.GMMHMM class
from hmmlearn import hmm
model=hmm.GMMHMM(n_components=5,n_mix=16,n_iter=10, covariance_type=’diag’)
important attributes:
model.gmms_, and
model.transmat_
Also have a look at hmm.GMM(n_components=n_mix) - this is an implementation of the GMM that comes as part of the hmmlearn library, and is separate from the mixture.GMM class provided by scikit-learn.
For reporting performance of the models, report the accuracy (percentage of observations classified correctly compared to the gold-standard).
You are asked to perform the following experiments and report on them, and also submit the code:
1- Initialize an HMM, but do not train it using fit(). Instead, train it manually by training separate GMMs (using the hmmlearn.GMM class) for each speaker and plugging it in the HMM (you can extract features of each speaker by looking at the gold-standard speaker labels). Report the accuracy by comparing the Viterbi output, and the gold-standard labels.
2- Experiment 1 assumes uniform transition matrix (0.2 for all elements). Perform step 1, but in addition, compute the transition matrix manually from the labels, and plug it in the HMM. Report the accuracy by comparing the Viterbi output, and the original labels. Is it performing better than before? Discuss your reasons.
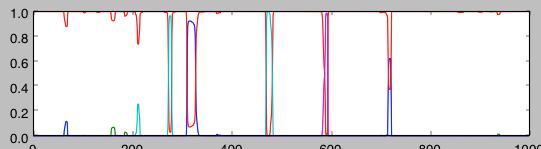
3- For model in experiment 2, plot the posterior probability of each state for each observation in 6000:7000 range (look up the methods available in GMMHMM and its parent classes). Describe the plots in your own words. The output should be something like the following:
4- Perform experiments 1-2, but train GMMs on corrupted speaker labels instead of gold-standard labels.
5- Initialize an HMM and train the HMM using EM (.fit() method) with 10 iterations (It takes several minutes). Report the accuracy by comparing the Viterbi output, and the original labels. Tip: you would notice that states may not necessarily represent the speakers as we have labeled them. So permute all possible speaker assignments (refer to itertools.permutations) and compute the maximum accuracy as current model’s accuracy (In real-world, slightly more complicated algorithms are used, but for this experiment, doing an exhaustive search is enough). Report the accuracy by comparing the Viterbi output, and the original labels. Is it performing better than before? Discuss your reasons.